论文:GraphScape: A Model for Automated Reasoning about Visualization Similarity and Sequencing
作者:Younghoon Kim, Kanit Wongsuphasawat, Jessica Hullman, Jeffrey Heer
发表:2017 CHI (Best paper honorable mention)
简介 在实际使用时,用户可能会有连续查看多个图表的需求,然而已有的推荐系统只关注单一图表。本文的作者考虑可视化之间的相似性和顺序,给出了 GraphScape——一个可以结合顺序评估变换成本的有向图模型。
比较图表转化类型
1、识别编辑操作:基于 vega-lite 范式,作者对所有原子操作(任意基于 vega-lite 的操作由一个或一组原子操作组成)进行总结。全部原子操作被分为三组,见下表。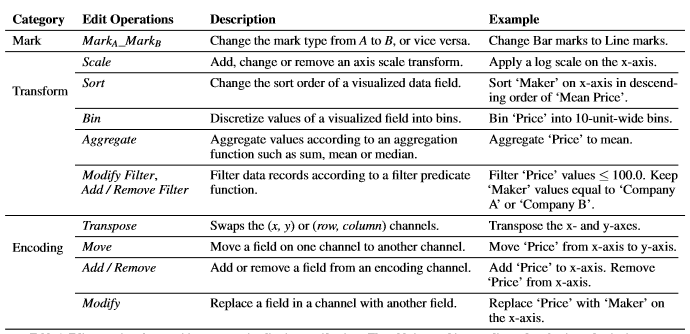
2、对编辑操作排序:为了计算转换成本,作者基于转换时的理解难度对编辑操作构建不等关系。由于原子操作数量过多,一一评价难度过大,作者首先基于语义对三大类的难度进行了排序:
标记类型:保留数据不变
数据转换:改变汇总级别或数据集合
可视编码:改变正在显示的内容
根据三者语义,理解成本是依次递增的。接下来,作者在每类类内执行了三元比较的自实验,比如考虑从一个柱状图变化为饼图好理解还是线图好理解等。最后,基于这份数据,做 GNMDS (广义非度量多维缩放) 投影。投影距离即转化成本。
3、导出编辑操作成本:从之前得到的初始差异模型中推导出整体的成本模型有如下挑战:
类间转化距离是否需要缩放?
多次操作叠加的成本不是简单的累加
生成的距离是对称的,然而实际转化成本不是
针对这些挑战,作者提出的解决方法是:在保留类间有序性的基础上,将不等式转化为线性规划问题。
实证研究
为了验证上述结论,也为了给出进一步研究的方向,作者招募了 51 个上可视化课程的学生进行了实验。在实验中,被试被要求想象自己需要以 ppt 的形式向别人介绍几组图表,为了让别人更好理解,需要对每组图表进行排序。作者分布针对七个主题进行了实验,结论如下:
(维度)增加 vs. 移除,没有明显差异
标记类型变化 vs. 轴变换,后者有明显难度
过滤 vs. 颠倒,后者有明显难度
(过滤)增加 vs. 移除,没有明显差异
总结 vs. 挖掘?偏好逐步挖掘
是否偏好编辑最小化?是
是否偏好子序列并行?是
GraphScape
GraphScape 模型考虑三个要素:V:Vega-lite 范式,E:编辑操作,有权,D:数据表
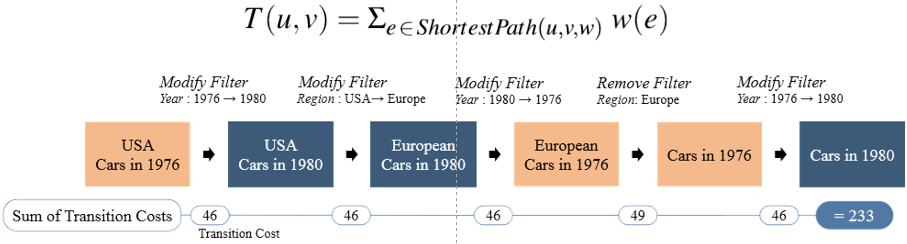
1、转化成本:两个阶段间转移成本:最短路径上的权重和
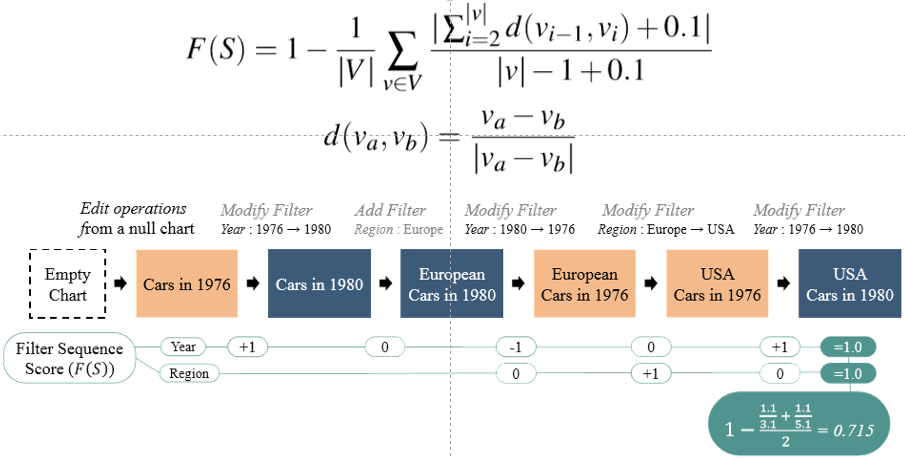
2、过滤顺序成本:过滤的谓词可以是等价,符合范围或者属于集合。这里只考虑等价,其他列入未来工作。相比于降序排序,升序排序更符合认知,公式中通过+0.1 对升序进行奖励。
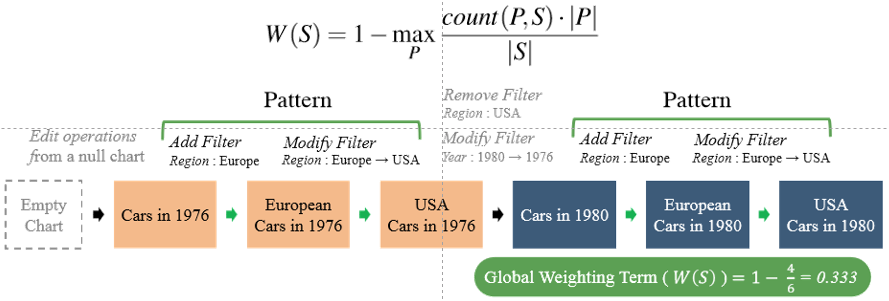
3、奖励子序列一致性:对子序列的出现和频次进行奖励。
4、总成本
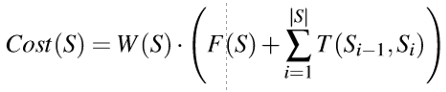
序列评分实验
1、实验设计:比较用户偏好和 GraphScape 的评估模型。被试为从 AMT 上招募的 55 人,平均 41 分钟完成全部内容,获得$6.5 报酬。具体任务为六组:对六个图表的五种排序打分(5 分制)。例子如下图。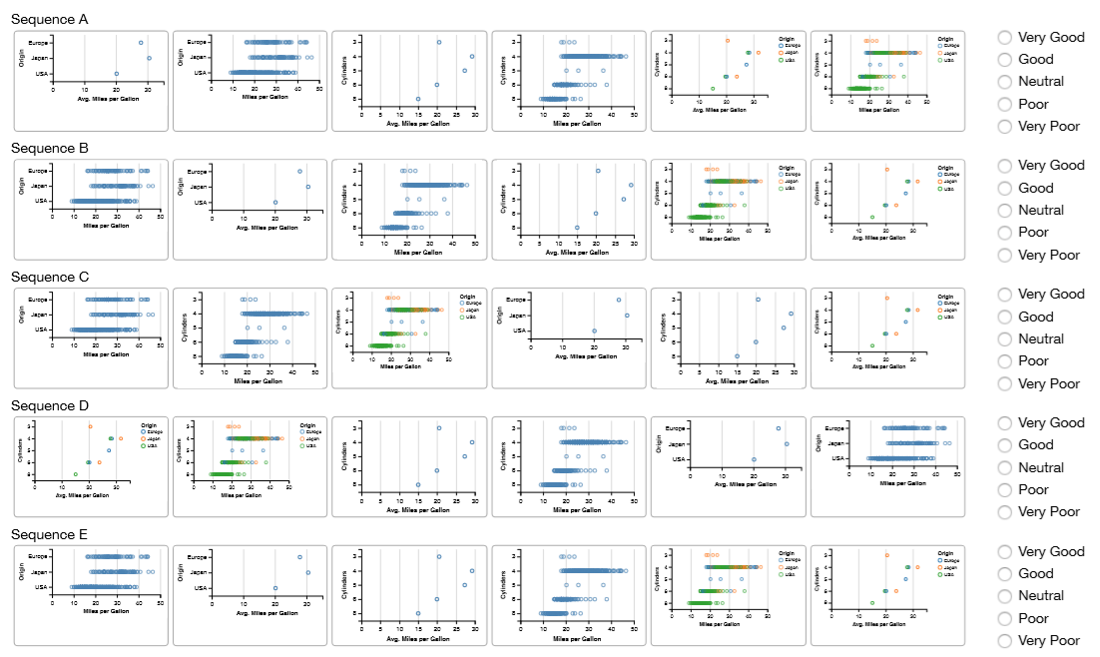
2、实验过程:
先观察图表,回答三个和图表相关问题。若回答错误证明没有认真看图,数据作废。
思考什么排序最好,点确认。
看系统给出的五种排序并打分。
描述原因,登记信息。
3、结果分析

多种分析结果显示:不同排序的得分有显著差异,和它们在任务中出现的位置没有显著关系。排名差异除了第四组以外都显著。GraphScape 模型推荐结果和用户排名显著相关。
应用
序列推荐:以目标函数的形式出现在优化问题中,结合用户交互推荐序列。
路径优化:定义动画分界点。
设计替代方案。
未来工作
拓展到更细致的范式
处理更复杂的谓词
学习用户决策语料库
考虑非线性模型
从可视化层面拓展到数据层面
在实验中考虑细微影响
✉️ wangxumeng@zju.edu.cn